What’s a Lectionary?
A lectionary, according to Wikipedia, is a listing of scripture readings for Christian or Judaic worship on a given day. The Roman Catholic Lectionary will contain a list of readings for a specific day that are on a 3-year cycle. Here is an example:
Thirtieth Sunday in Ordinary Time
Lectionary: 149
Reading 1: Jer 31:7-9
Psalm: Ps 126:1-2, 2-3, 4-5, 6
Reading 2: Heb 5:1-6
Gospel: Mk 10:46-52
As a Catholic, I’ve often wondered how much of the Bible is included in the lectionary. Fortunately, Felix Just, S.J., Ph.D. compiled a website with statistics on many aspects of the lectionary which help to answer this question.
His analysis shows that a Catholic who attends Mass on Sundays and Feasts (but not weekdays) would hear ~ 4% of the Old Testament (excluding Psalms) and ~ 41% of the New Testament. Wow - this was a shock to me! I bet if you ask around you’ll hear that many Catholics think the lectionary includes the whole Bible. To be fair, these numbers do get a bit higher if you include the complete lectionary (with weekdays). The total coverage of the Old Testament is ~14% (again excluding Psalms) and for the New Testament it is ~72%.
Since I’m a Data Scientist, I naturally wanted to dig into these numbers and ask more questions. The summary tables nicely show which books are covered and which are not. But what verses are actually covered? Is there something unique about those verses vs. those in the Lectionary (e.g. different sorts of themes)? In the future I plan to write another post on understanding the content via Natural Language Processing. For this post, I’ll focus on creating a single visualization of the lectionary coverage for Sundays and Major Feasts to help me understand what parts are covered at a glance.
Ok Cool, But Isn’t the Lectionary a Book?

Yes, the lectionary is traditionally a book. But it’s the 21st century and luckily someone else has transcribed this into an electronic listing so I didn’t have to do it. The data necessary includes the Sunday Lectionary and a pair of reference guides that tell us how many chapters/verses are in each book of the Bible (Old Testament Reference, New Testament Reference). I could have played with web scraping but there were only a few tables so I just copied the tables in Felix’s website into Excel files (link to data files).
Code
##############
## Packages ##
##############
library(readxl)
library(scales)
library(knitr)
library(tidyverse)
library(aveytoolkit)
###############
## Variables ##
###############
data_dir <- "plotBible"
OTRefFile <- file.path(data_dir, "OldTestamentReference.xlsx")
NTRefFile <- file.path(data_dir, "NewTestamentReference.xlsx")
abbrevFile <- file.path(data_dir, "BibleAbbreviations.xlsx")
LectSundaysFile <- file.path(data_dir, "Lectionary-SundaysAndFeasts.xlsx")
###############
## Functions ##
###############
source(file.path(data_dir, "helperFunctions.R"))Code
########################
## Read in references ##
########################
testaments <- c("OT", "NT")
abbrev <- map(testaments, ~read_excel(abbrevFile, sheet = .x))
names(abbrev) <- testaments
## Old Testament
OTsections <- c("Torah", "Historical", "Wisdom", "MajorProphets", "MinorProphets")
OTref <- map_df(OTsections, function(OTsection) {
read_excel(OTRefFile, sheet = OTsection, na = ".") %>%
mutate(Section = OTsection)
}) %>%
rename(Book = `Book Name`) %>%
gather(matches("[0-9]+"), key = "Chapter", value = "Verses") %>%
filter(!is.na(Verses)) %>%
select(Section, Book, Chapter, Verses) %>%
mutate(Book = factor(Book, # Order books in factor levels
levels = abbrev$OT$Name),
Abbrv = abbrev$OT$Abbreviation[match(Book, abbrev$OT$Name)],
Chapter = as.numeric(Chapter)) %>%
arrange(Book) %>%
mutate(Abbrv = factor(Abbrv, levels = unique(Abbrv)))
## Munge so that reference contains 1 row for every verse in the order they
## appear in the Old Testament with a `Pos` column to denote the position of the
## verse.
OTref2Pos <- OTref %>%
arrange(Book, Chapter) %>%
mutate(Verse = map(Verses, function(x) 1:x)) %>%
unnest() %>%
mutate(Chapter_Verse = paste(Chapter, Verse, sep = ':')) %>%
mutate(Pos = 1:n()) %>%
mutate(Testament = "Old")
## New Testament
NTsections <- c("Gospels", "NT")
NTref <- map_df(NTsections, function(NTsection) {
read_excel(NTRefFile, sheet = NTsection, na = ".") %>%
mutate(Section = NTsection) %>%
mutate_at(vars(matches("[0-9]+")),
funs(as.integer(str_replace(., fixed("*"), ""))))
}) %>%
rename(Abbrv = `Book Name`) %>%
gather(matches("[0-9]+"), key = "Chapter", value = "Verses") %>%
filter(!is.na(Verses)) %>%
select(Section, Abbrv, Chapter, Verses) %>%
mutate(Abbrv = factor(Abbrv,
levels = abbrev$NT$Abbreviation),
Book = abbrev$NT$Name[match(Abbrv, abbrev$NT$Abbreviation)],
Chapter = as.numeric(Chapter)) %>%
arrange(Abbrv) %>%
mutate(Book = factor(Book, levels = unique(Book)))
## Munge so that reference contains 1 row for every verse in the order they
## appear in the New Testament with a `Pos` column to denote the position of the
## verse.
NTref2Pos <- NTref %>%
arrange(Book, Chapter) %>%
mutate(Verse = map(Verses, function(x) 1:x)) %>%
unnest() %>%
mutate(Chapter_Verse = paste(Chapter, Verse, sep = ':')) %>%
mutate(Pos = 1:n()) %>%
mutate(Testament = "New")
ref2Pos <- bind_rows(OTref2Pos, NTref2Pos) %>%
mutate(Pos = 1:n())Reference Data
There is a lot of data transformation necessary but in the end, we have a data frame with 35,524 rows which contains 1 row for every verse in the Catholic Bible. This will be used as the reference to compare the lectionary to. Below I show part of the table containing the first and last 6 verses.
Code
ref2Pos %>%
select(Testament, Section, Book, Chapter, Verse, Pos) %>%
head() %>%
knitr::kable()| Testament | Section | Book | Chapter | Verse | Pos |
|---|---|---|---|---|---|
| Old | Torah | Genesis | 1 | 1 | 1 |
| Old | Torah | Genesis | 1 | 2 | 2 |
| Old | Torah | Genesis | 1 | 3 | 3 |
| Old | Torah | Genesis | 1 | 4 | 4 |
| Old | Torah | Genesis | 1 | 5 | 5 |
| Old | Torah | Genesis | 1 | 6 | 6 |
Code
ref2Pos %>%
select(Testament, Section, Book, Chapter, Verse, Pos) %>%
tail() %>%
knitr::kable()| Testament | Section | Book | Chapter | Verse | Pos |
|---|---|---|---|---|---|
| New | NT | Revelation | 22 | 16 | 35519 |
| New | NT | Revelation | 22 | 17 | 35520 |
| New | NT | Revelation | 22 | 18 | 35521 |
| New | NT | Revelation | 22 | 19 | 35522 |
| New | NT | Revelation | 22 | 20 | 35523 |
| New | NT | Revelation | 22 | 21 | 35524 |
Lectionary Data
Code
###################################################
## Read in the Lectionary for Sundays and Feasts ##
###################################################
readings <- c("OT", "Psalm", "NT", "Gospel")
LectSundays <- map(readings, ~read_excel(LectSundaysFile, sheet = .x))
names(LectSundays) <- readings
SunLect <- bind_rows(LectSundays) %>%
tbl_df() %>%
separate(LectNum_Year, c("LectNum", "Year"), sep = '-') %>%
mutate(YearA = grepl("A", Year),
YearB = grepl("B", Year),
YearC = grepl("C", Year))Below are some entries in the lectionary including the Reading as well as the Year in the 3-year cycle (ABC means read in years A, B, and C). For this analysis, I’ll ignore the Year and just consider the coverage over the whole 3-year cycle.
Code
SunLect %>%
select(Reading, LectNum, Year, Day) %>%
head() %>%
kable()| Reading | LectNum | Year | Day |
|---|---|---|---|
| Gen 1:1-2:2 or 1:1, 26-31a | 41 | ABC | Easter Vigil (1st Reading) |
| Gen 2:7-9; 3:1-7 | 22 | A | 1st Sunday of Lent |
| Gen 2:18-24 | 140 | B | 27th Sunday in Ordinary Time |
| Gen 3:9-15 | 89 | B | 10th Sunday in Ordinary Time |
| Gen 9:8-15 | 23 | B | 1st Sunday of Lent |
| Gen 11:1-9 | 62 | ABC | Pentecost Sunday: Vigil Mass (Option 1) |
Parsing Verses
The crucial part is matching the Reading to the reference. This seems straightforward but can be very tricky in some cases. I wrote a basic parser (see code) to handle the most common cases. It ignores some aspects such as the “or” option as in the first row of the table above. Usually an “or” option gives a longer form followed by a shorter form (subset of the first option) so I’ll only consider the longer forms.
Each set of continuous verses gets stored in a new data frame by the parser. For example, Gen 1:1-2:2 or 1:1, 26-31a will get parsed to:
Code
ParseFull(SunLect$Reading[1])## start end Abbrv
## 1 1:1 2:2 Genand Gen 2:7-9; 3:1-7 will get parsed to:
Code
ParseFull(SunLect$Reading[2])## start end Abbrv
## 1 2:7 2:9 Gen
## 2 3:1 3:7 GenThen, once each reading from the lectionary is parsed, it gets matched back to the reference.
Code
## Apply parser on the full Sunday Lectionary
res <- SunLect %>%
mutate(Pos = map(Reading, function(x) {
## cat(x, sep = '\n') # debugging
ParseFull(x) %>%
left_join(ref2Pos, by = c(start = "Chapter_Verse", Abbrv = "Abbrv")) %>%
left_join(ref2Pos, by = c(end = "Chapter_Verse", Abbrv = "Abbrv")) %>%
rowwise() %>%
do(data.frame(Pos = if (any(is.na(.))) {
NA
} else {
.$Pos.x:.$Pos.y
}
)) %>%
pull(Pos)}))
## Combine the results with the reference
comb_dat <- res %>%
unnest(Pos) %>%
left_join(ref2Pos, by = "Pos")So each reading is parsed into multiple segments and then mapped onto the position variable (Pos) from the Reference. The result for one reading looks like this:
Code
comb_dat %>%
select(Reading, Section, Book, Chapter, Verse, Pos) %>%
filter(Reading == "Isa 63:16b-17, 19b; 64:2-7") %>%
kable()| Reading | Section | Book | Chapter | Verse | Pos |
|---|---|---|---|---|---|
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 63 | 16 | 22923 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 63 | 17 | 22924 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 63 | 19 | 22926 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 2 | 22928 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 3 | 22929 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 4 | 22930 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 5 | 22931 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 6 | 22932 |
| Isa 63:16b-17, 19b; 64:2-7 | MajorProphets | Isaiah | 64 | 7 | 22933 |
Visualize the Lectionary Coverage
The inspiration behind this visualization is picturing the whole Bible as a bookshelf. There is one row for each major section (e.g., Torah, Minor Prophets, Gospels) and each section is made up of multiple books. In the visualization, lines are used to indicate coverage of a particular verse in the lectionary.
Code
## Get all section lengths
sections <- ref2Pos %>%
select(Section, Abbrv) %>%
distinct() %>%
group_by(Section) %>%
mutate(Abbrv = list(Abbrv)) %>%
distinct() %>%
deframe()
sectPos <- map_int(names(sections), function(sect) {
abbrvs <- sections[[sect]]
lastAbbrv <- abbrvs[length(abbrvs)]
maxPos <- ref2Pos %>%
filter(Abbrv == lastAbbrv) %>%
pull(Pos) %>%
max()
return(maxPos)
})
names(sectPos) <- names(sections)
sectPos2 <- c(0, sectPos[-length(sectPos)])
names(sectPos2) <- names(sectPos)
sectLength <- sectPos - sectPos2
## Tweak Section Labels for Plot
sectLabels <- names(sections) %>%
paste0(., " (V=", comma(sectLength[.]), ")") %>%
str_replace("Prophets", " Prophets") %>%
str_replace("NT", "New Testament") %>%
setNames(names(sections))
## Generate plotting data
dat <- comb_dat %>%
filter(!is.na(Pos)) %>%
select(Section, Abbrv, Chapter, Verse, Pos) %>%
mutate(Pos = (Pos - sectPos2[Section]) / sectLength[Section]) %>%
mutate(SectionLabel = factor(sectLabels[Section],
levels = sectLabels)) %>%
mutate(Label = paste0(Abbrv, " ", Chapter, ":", Verse)) %>%
distinct() # ignore how many times something appeared (read 2 or 3 times)
book_dat <- ref2Pos %>%
mutate(Abbrv = factor(Abbrv, levels = unique(Abbrv))) %>%
mutate(Pos = (Pos - sectPos2[Section]) / sectLength[Section]) %>%
mutate(SectionLabel = factor(sectLabels[Section],
levels = sectLabels)) %>%
group_by(SectionLabel, Abbrv) %>%
summarize(Pos = min(Pos)) %>%
ungroup() %>%
group_by(SectionLabel) %>%
mutate(y = rep(c(0, 0.33, 0.66, 1), length.out = n())) %>%
ungroup()
## Create the plot
gg <- ggplot(dat, x = 0, y = 1) +
geom_vline(aes(xintercept = Pos, color = Abbrv), show.legend = FALSE) +
geom_label(data = book_dat, aes(x = Pos, y = y, label = Abbrv),
hjust = 0, size = 3.5) +
scale_x_continuous(labels = percent) +
scale_y_continuous(labels = NULL, breaks = NULL) +
xlab("") +
ylab("") +
ggtitle(paste("Bible Coverage of Catholic Lectionary for",
"Sundays and Major Feasts", sep = '\n')) +
labs(caption = "Three Year Cycle") +
facet_grid(SectionLabel ~ ., scales = "fixed") +
getBaseTheme() +
theme(strip.text = element_text(size = 10, face = "bold"))
plot(gg)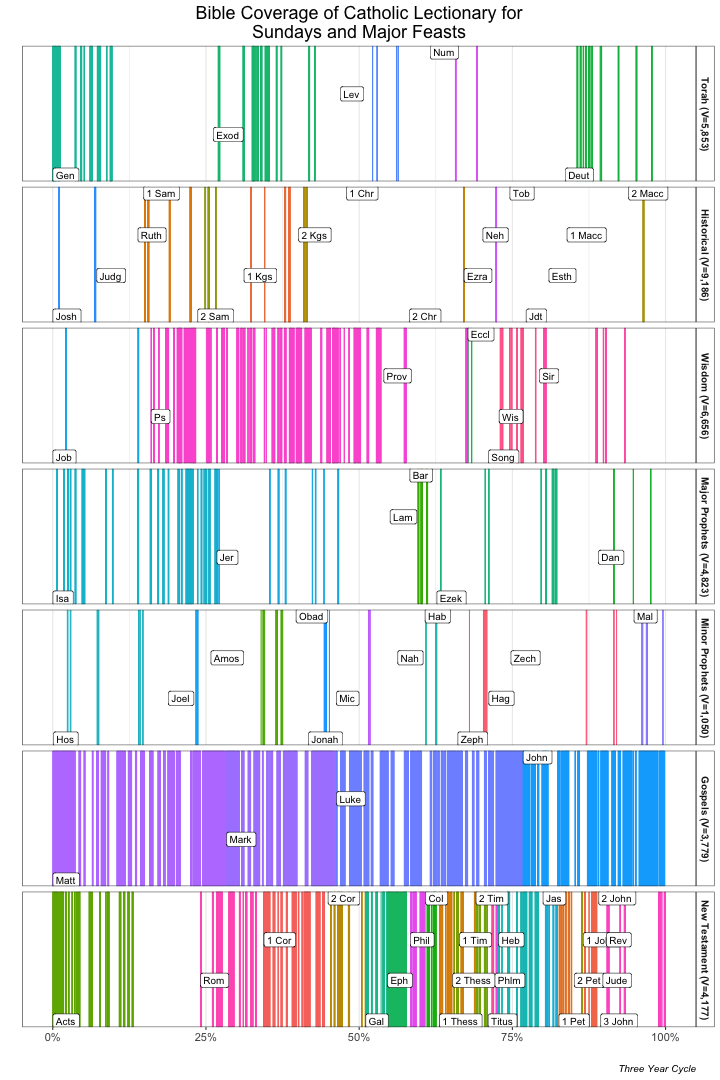
Code
GetCoverage <- function(abbrv) {
tot <- ref2Pos %>%
filter(Abbrv == abbrv) %>%
select(Chapter_Verse) %>%
distinct() %>%
nrow()
cov <- dat %>%
filter(Abbrv == abbrv) %>%
select(Pos) %>%
distinct() %>%
nrow()
return(cov/tot)
}The amount of white space clearly shows what parts of the Bible are not contained in the lectionary. For example, in the New Testament section (bottom row of the “bookshelf”), it is apparent that little of the book of Acts (coverage = 17%) or Revelation (coverage = 10%) are in the Sunday lectionary.
While most of the Old Testament is sparsely covered, the Psalms (abbreviated Ps) are one of the most covered books at 21% coverage. One of the drawbacks of this visualization is that each row contains a different number of verses so that the visual sense of “fullness” can be deceiving.
Acknowledgments
Huge kudos to Felix Just, S.J., Ph.D. for compiling these resources: